
Documentation 📖
Your guide to using FlowCanvas Visual Scripting in Unity

Functions
The Functions node category, contains all those nodes which actually make something happen in your application, like moving objects, destroying objects, settings properties and so on. The Functions category itself is further divided into two subcategories for clarity purposes, those being the Reflected Functions and Implemented Functions categories.
- Functions/Reflected category, includes all the nodes that are generated through reflection for the types specified in the Preferred Types Editor. This is the category of nodes which you will use to access the Unity, your own code, or any 3rd Party API for its methods, constructors, properties, fields, or events.
- Functions/Implemented category, is a collection of utility nodes that come with FlowCanvas, but which are neither directly related to any existing type, nor are generated through reflection.
When working with any of the nodes within any of the two above sub-categories, there are two types of Function nodes that will be encountered depending on the functionality of the node.
Callable Functions
Callable Functions have no Value Outputs unless one or more of their parameters is an ‘out’ (a C# language feature that is supported in FlowCanvas), but rather a number of different Value Inputs for setting the parameters of the function. Callable Functions always have 1 Flow Input, which simply refers to “Execute” the function, as well as 1 Flow Output which will be called once after the function is done.

Non-Callable Functions
Non-Callable Function nodes can easily be identified by their lack of any Flow Input or Flow Output ports. Such non-callable function nodes are always the ones that return a value through a Value Output port and which nodes are usually responsible just for manipulating data, math operations or getting data, rather than actually “making stuff happen” within the application. The Random Range function node is a good example, where it simply returns a random value between Min and Max, rather than actually doing something by itself.

By default, a Non-Callable Function node does not require Flow execution to work and as such, they have no Flow Input nor Flow Output ports. You simply connect the Value output to some other node you wish to feed the result value. Having said that, there are some rare cases in which you would prefer to have control over when the node is called, by explicitly connecting a Flow into the node. In such cases, you can make the node “Callable” by ticking the respective toggle within the node inspector.

Having done that, the node will be converted to a Callable Function as shown above where 1 Flow input and 1 Flow output will appear. As such, the Value output of the node will only be set whenever you explicitly call the node with a Flow signal.
Function Params Array
C# has a language feature called params array. This basically allows a function to take up to any number of optional parameters (of one type), but instead of providing the function in the form of an array or a list, the different parameters can be provided separately on a one-to-one basis.
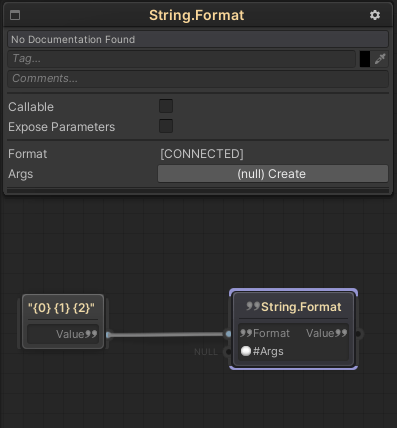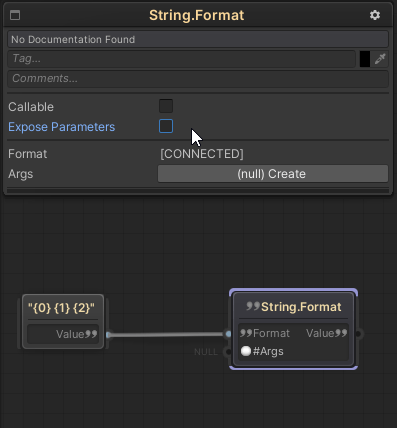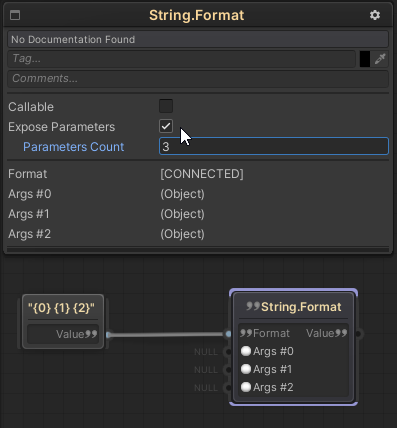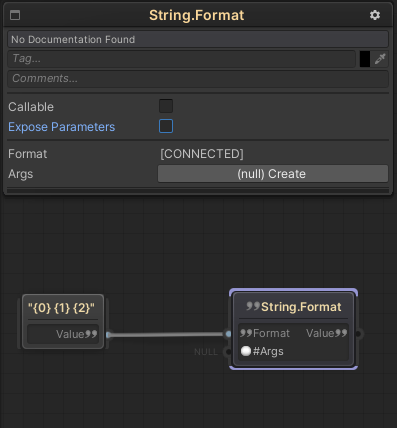
FlowCanvas supports this feature within the editor as well, making it a lot easier to provide multiple function parameters when the function supports the params array feature. When that is the case, a special option in the node’s inspector panel for the function will show to “Expose Parameters”, along with the number of parameters to be exposed. Enabling this option will turn the input parameter port from being an Array type to multiple separate parameter ports of that type. This makes it easier to connect multiple inputs without the need to create an array.
Following is a node for the “String.Format” function, which supports a string params array as one of the inputs, and how changing the type of the params to “Expose Parameters” affects the node.
© Paradox Notion 2015-2025. All rights reserved.